|
CMSIS-DSP
CMSIS DSP Software Library
|

|
|
CMSIS-DSP
CMSIS DSP Software Library
|
|
Multiplies two matrices.
\[ \begin{pmatrix} a_{1,1} & a_{1,2} & a_{1,3} \\ a_{2,1} & a_{2,2} & a_{2,3} \\ a_{3,1} & a_{3,2} & a_{3,3} \\ \end{pmatrix} \begin{pmatrix} b_{1,1} & b_{1,2} & b_{1,3} \\ b_{2,1} & b_{2,2} & b_{2,3} \\ b_{3,1} & b_{3,2} & b_{3,3} \\ \end{pmatrix} = \begin{pmatrix} a_{1,1} b_{1,1}+a_{1,2} b_{2,1}+a_{1,3} b_{3,1} & a_{1,1} b_{1,2}+a_{1,2} b_{2,2}+a_{1,3} b_{3,2} & a_{1,1} b_{1,3}+a_{1,2} b_{2,3}+a_{1,3} b_{3,3} \\ a_{2,1} b_{1,1}+a_{2,2} b_{2,1}+a_{2,3} b_{3,1} & a_{2,1} b_{1,2}+a_{2,2} b_{2,2}+a_{2,3} b_{3,2} & a_{2,1} b_{1,3}+a_{2,2} b_{2,3}+a_{2,3} b_{3,3} \\ a_{3,1} b_{1,1}+a_{3,2} b_{2,1}+a_{3,3} b_{3,1} & a_{3,1} b_{1,2}+a_{3,2} b_{2,2}+a_{3,3} b_{3,2} & a_{3,1} b_{1,3}+a_{3,2} b_{2,3}+a_{3,3} b_{3,3} \\ \end{pmatrix} \]
Matrix multiplication is only defined if the number of columns of the first matrix equals the number of rows of the second matrix. Multiplying an M x N matrix with an N x P matrix results in an M x P matrix. When matrix size checking is enabled, the functions check: (1) that the inner dimensions of pSrcA and pSrcB are equal; and (2) that the size of the output matrix equals the outer dimensions of pSrcA and pSrcB.
Multiplies two matrices.
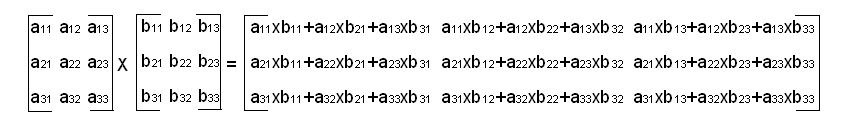
Matrix multiplication is only defined if the number of columns of the first matrix equals the number of rows of the second matrix. Multiplying an M x N matrix with an N x P matrix results in an M x P matrix. When matrix size checking is enabled, the functions check: (1) that the inner dimensions of pSrcA and pSrcB are equal; and (2) that the size of the output matrix equals the outer dimensions of pSrcA and pSrcB.
| arm_status arm_mat_mult_f16 | ( | const arm_matrix_instance_f16 * | pSrcA, |
| const arm_matrix_instance_f16 * | pSrcB, | ||
| arm_matrix_instance_f16 * | pDst | ||
| ) |
Floating-point matrix multiplication.
| [in] | *pSrcA | points to the first input matrix structure |
| [in] | *pSrcB | points to the second input matrix structure |
| [out] | *pDst | points to output matrix structure |
ARM_MATH_SIZE_MISMATCH or ARM_MATH_SUCCESS based on the outcome of size checking. | arm_status arm_mat_mult_f32 | ( | const arm_matrix_instance_f32 * | pSrcA, |
| const arm_matrix_instance_f32 * | pSrcB, | ||
| arm_matrix_instance_f32 * | pDst | ||
| ) |
Floating-point matrix multiplication.
| [in] | *pSrcA | points to the first input matrix structure |
| [in] | *pSrcB | points to the second input matrix structure |
| [out] | *pDst | points to output matrix structure |
ARM_MATH_SIZE_MISMATCH or ARM_MATH_SUCCESS based on the outcome of size checking. | arm_status arm_mat_mult_f64 | ( | const arm_matrix_instance_f64 * | pSrcA, |
| const arm_matrix_instance_f64 * | pSrcB, | ||
| arm_matrix_instance_f64 * | pDst | ||
| ) |
Floating-point matrix multiplication.
| [in] | *pSrcA | points to the first input matrix structure |
| [in] | *pSrcB | points to the second input matrix structure |
| [out] | *pDst | points to output matrix structure |
ARM_MATH_SIZE_MISMATCH or ARM_MATH_SUCCESS based on the outcome of size checking. | arm_status arm_mat_mult_fast_q15 | ( | const arm_matrix_instance_q15 * | pSrcA, |
| const arm_matrix_instance_q15 * | pSrcB, | ||
| arm_matrix_instance_q15 * | pDst, | ||
| q15_t * | pState | ||
| ) |
Q15 matrix multiplication (fast variant).
Q15 matrix multiplication (fast variant) for Cortex-M3 and Cortex-M4.
| [in] | pSrcA | points to the first input matrix structure |
| [in] | pSrcB | points to the second input matrix structure |
| [out] | pDst | points to output matrix structure |
| [in] | pState | points to the array for storing intermediate results |
| arm_status arm_mat_mult_fast_q31 | ( | const arm_matrix_instance_q31 * | pSrcA, |
| const arm_matrix_instance_q31 * | pSrcB, | ||
| arm_matrix_instance_q31 * | pDst | ||
| ) |
Q31 matrix multiplication (fast variant).
Q31 matrix multiplication (fast variant) for Cortex-M3 and Cortex-M4.
| [in] | pSrcA | points to the first input matrix structure |
| [in] | pSrcB | points to the second input matrix structure |
| [out] | pDst | points to output matrix structure |
| arm_status arm_mat_mult_opt_q31 | ( | const arm_matrix_instance_q31 * | pSrcA, |
| const arm_matrix_instance_q31 * | pSrcB, | ||
| arm_matrix_instance_q31 * | pDst, | ||
| q31_t * | pState | ||
| ) |
Q31 matrix multiplication.
| [in] | pSrcA | points to the first input matrix structure |
| [in] | pSrcB | points to the second input matrix structure |
| [out] | pDst | points to output matrix structure |
| [in] | pState | points to the array for storing intermediate results |
| arm_status arm_mat_mult_q15 | ( | const arm_matrix_instance_q15 * | pSrcA, |
| const arm_matrix_instance_q15 * | pSrcB, | ||
| arm_matrix_instance_q15 * | pDst, | ||
| q15_t * | pState | ||
| ) |
Q15 matrix multiplication.
| [in] | pSrcA | points to the first input matrix structure |
| [in] | pSrcB | points to the second input matrix structure |
| [out] | pDst | points to output matrix structure |
| [in] | pState | points to the array for storing intermediate results |
| arm_status arm_mat_mult_q31 | ( | const arm_matrix_instance_q31 * | pSrcA, |
| const arm_matrix_instance_q31 * | pSrcB, | ||
| arm_matrix_instance_q31 * | pDst | ||
| ) |
Q31 matrix multiplication.
| [in] | pSrcA | points to the first input matrix structure |
| [in] | pSrcB | points to the second input matrix structure |
| [out] | pDst | points to output matrix structure |
| arm_status arm_mat_mult_q7 | ( | const arm_matrix_instance_q7 * | pSrcA, |
| const arm_matrix_instance_q7 * | pSrcB, | ||
| arm_matrix_instance_q7 * | pDst, | ||
| q7_t * | pState | ||
| ) |
Q7 matrix multiplication.
| [in] | pSrcA | points to the first input matrix structure |
| [in] | pSrcB | points to the second input matrix structure |
| [out] | pDst | points to output matrix structure |
| [in] | pState | points to the array for storing intermediate results |