|
CMSIS-NN
Version 1.3.0
CMSIS NN Software Library
|
|
CMSIS-NN
Version 1.3.0
CMSIS NN Software Library
|
This user manual describes the CMSIS NN software library, a collection of efficient neural network kernels developed to maximize the performance and minimize the memory footprint of neural networks on Cortex-M processor cores.
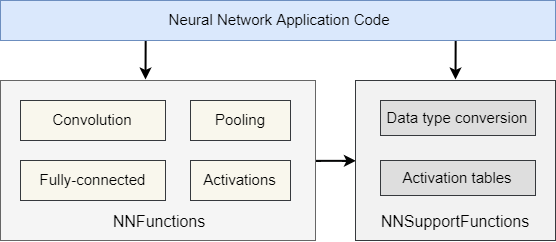
The library is divided into a number of functions each covering a specific category:
The library has separate functions for operating on different weight and activation data types including 8-bit integers (q7_t) and 16-bit integers (q15_t). The descrition of the kernels are included in the function description. The implementation details are also described in this paper [1].
The functions can be classified into two segments
The legacy functions can be identified with their suffix of _q7 or _q15 and are no new development is done there. The article in [2] describes in detail how to run a network using the legacy functions.
The functions supporting TensorFlow Lite framework is identified by the _s8 suffix and can be invoked from TFL micro. The functions are bit exact to TensorFlow Lite. Refer to the TensorFlow's documentation in [3] on how to run a TensorFlow Lite model using optimized CMSIS-NN kernels.
The library ships with a number of examples which demonstrate how to use the library functions.
Each library project have different pre-processor macros.
Define macro ARM_MATH_DSP, If the silicon supports DSP instructions(DSP extension).
Define macro ARM_MATH_MVEI, If the silicon supports M-Profile Vector Extension.
Define macro ARM_MATH_BIG_ENDIAN to build the library for big endian targets. This is supported only for the legacy functions i.e, functions targetted at TensorFlow Lite do not support big endianness. By default library builds for little endian targets.
Define macro ARM_NN_TRUNCATE to use floor instead of round-to-the-nearest-int for the computation.
Starting from the 1.4.0 next release, CMSIS-NN will gradually switch to a new API interface to:
The upcoming API interface change will be based on "struct" and only affect the TensorFlowLite micro compliant APIs [4] (functions with _s8 suffix)
Below you can find a snapshot of how the new API interface will look like (names can change)
i.e. arm_convolve_1x1_s8_fast
| Current API interface | New API interface proposal |
|---|---|
| const q7_t *input | const cmsis_nn_context &ctx |
| const uint16_t input_x | const cmsis_nn_conv_params ¶ms |
| const uint16_t input_y | const cmsis_nn_dims &input_dims |
| const uint16_t input_ch | const q7_t *input_data |
| const uint16_t input_batches | const cmsis_nn_dims &filter_dims |
| const q7_t *kernel | const q7_t *filter_data |
| const uint16_t output_ch | const cmsis_nn_dims &bias_dims |
| const uint16_t pad_x | const q31_t *bias_data |
| const uint16_t pad_y | const cmsis_nn_dims &output_dims |
| const uint16_t stride_x | q7_t *output_data |
| const uint16_t stride_y | |
| const int32_t *bias | |
| q7_t *output | |
| const int32_t *output_shift | |
| const int32_t *output_mult | |
| const int32_t out_offset | |
| const int32_t input_offset | |
| const int32_t out_activation_min | |
| const int32_t out_activation_max | |
| const uint16_t output_x | |
| const uint16_t output_y | |
| q15_t *buffer_a |
Copyright (C) 2010-2019 Arm Limited. All rights reserved.
[1] CMSIS-NN: Efficient Neural Network Kernels for Arm Cortex-M CPUs https://arxiv.org/abs/1801.06601
[2] Converting a Neural Network for Arm Cortex-M with CMSIS-NN https://developer.arm.com/solutions/machine-learning-on-arm/developer-material/how-to-guides/converting-a-neural-network-for-arm-cortex-m-with-cmsis-nn/single-page [3] https://www.tensorflow.org/lite/microcontrollers/library
[4] https://github.com/ARM-software/CMSIS_5/tree/develop/CMSIS/NN#legacy-vs-tfl-micro-compliant-apis

