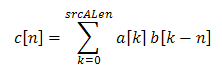|
| void | arm_correlate_f16 (const float16_t *pSrcA, uint32_t srcALen, const float16_t *pSrcB, uint32_t srcBLen, float16_t *pDst) |
| | Correlation of floating-point sequences. More...
|
| |
| void | arm_correlate_f32 (const float32_t *pSrcA, uint32_t srcALen, const float32_t *pSrcB, uint32_t srcBLen, float32_t *pDst) |
| | Correlation of floating-point sequences. More...
|
| |
| void | arm_correlate_f64 (const float64_t *pSrcA, uint32_t srcALen, const float64_t *pSrcB, uint32_t srcBLen, float64_t *pDst) |
| | Correlation of floating-point sequences. More...
|
| |
| void | arm_correlate_fast_opt_q15 (const q15_t *pSrcA, uint32_t srcALen, const q15_t *pSrcB, uint32_t srcBLen, q15_t *pDst, q15_t *pScratch) |
| | Correlation of Q15 sequences (fast version). More...
|
| |
| void | arm_correlate_fast_q15 (const q15_t *pSrcA, uint32_t srcALen, const q15_t *pSrcB, uint32_t srcBLen, q15_t *pDst) |
| | Correlation of Q15 sequences (fast version). More...
|
| |
| void | arm_correlate_fast_q31 (const q31_t *pSrcA, uint32_t srcALen, const q31_t *pSrcB, uint32_t srcBLen, q31_t *pDst) |
| | Correlation of Q31 sequences (fast version). More...
|
| |
| void | arm_correlate_opt_q15 (const q15_t *pSrcA, uint32_t srcALen, const q15_t *pSrcB, uint32_t srcBLen, q15_t *pDst, q15_t *pScratch) |
| | Correlation of Q15 sequences. More...
|
| |
| void | arm_correlate_opt_q7 (const q7_t *pSrcA, uint32_t srcALen, const q7_t *pSrcB, uint32_t srcBLen, q7_t *pDst, q15_t *pScratch1, q15_t *pScratch2) |
| | Correlation of Q7 sequences. More...
|
| |
| void | arm_correlate_q15 (const q15_t *pSrcA, uint32_t srcALen, const q15_t *pSrcB, uint32_t srcBLen, q15_t *pDst) |
| | Correlation of Q15 sequences. More...
|
| |
| void | arm_correlate_q31 (const q31_t *pSrcA, uint32_t srcALen, const q31_t *pSrcB, uint32_t srcBLen, q31_t *pDst) |
| | Correlation of Q31 sequences. More...
|
| |
| void | arm_correlate_q7 (const q7_t *pSrcA, uint32_t srcALen, const q7_t *pSrcB, uint32_t srcBLen, q7_t *pDst) |
| | Correlation of Q7 sequences. More...
|
| |
Correlation is a mathematical operation that is similar to convolution. As with convolution, correlation uses two signals to produce a third signal. The underlying algorithms in correlation and convolution are identical except that one of the inputs is flipped in convolution. Correlation is commonly used to measure the similarity between two signals. It has applications in pattern recognition, cryptanalysis, and searching. The CMSIS library provides correlation functions for Q7, Q15, Q31 and floating-point data types. Fast versions of the Q15 and Q31 functions are also provided.
- Algorithm
- Let
a[n] and b[n] be sequences of length srcALen and srcBLen samples respectively. The convolution of the two signals is denoted by
c[n] = a[n] * b[n]
In correlation, one of the signals is flipped in time
c[n] = a[n] * b[-n]
- and this is mathematically defined as
- The
pSrcA points to the first input vector of length srcALen and pSrcB points to the second input vector of length srcBLen. The result c[n] is of length 2 * max(srcALen, srcBLen) - 1 and is defined over the interval n=0, 1, 2, ..., (2 * max(srcALen, srcBLen) - 2). The output result is written to pDst and the calling function must allocate 2 * max(srcALen, srcBLen) - 1 words for the result.
- Note
- The
pDst should be initialized to all zeros before being used.
- Fixed-Point Behavior
- Correlation requires summing up a large number of intermediate products. As such, the Q7, Q15, and Q31 functions run a risk of overflow and saturation. Refer to the function specific documentation below for further details of the particular algorithm used.
- Fast Versions
- Fast versions are supported for Q31 and Q15. Cycles for Fast versions are less compared to Q31 and Q15 of correlate and the design requires the input signals should be scaled down to avoid intermediate overflows.
- Opt Versions
- Opt versions are supported for Q15 and Q7. Design uses internal scratch buffer for getting good optimisation. These versions are optimised in cycles and consumes more memory (Scratch memory) compared to Q15 and Q7 versions of correlate
| void arm_correlate_f16 |
( |
const float16_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
const float16_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
float16_t * |
pDst |
|
) |
| |
- Parameters
-
| [in] | pSrcA | points to the first input sequence |
| [in] | srcALen | length of the first input sequence |
| [in] | pSrcB | points to the second input sequence |
| [in] | srcBLen | length of the second input sequence |
| [out] | pDst | points to the location where the output result is written. Length 2 * max(srcALen, srcBLen) - 1. |
- Returns
- none
- Parameters
-
| [in] | pSrcA | points to the first input sequence |
| [in] | srcALen | length of the first input sequence |
| [in] | pSrcB | points to the second input sequence |
| [in] | srcBLen | length of the second input sequence |
| [out] | pDst | points to the location where the output result is written. Length 2 * max(srcALen, srcBLen) - 1. |
- Returns
- none
- Parameters
-
| [in] | pSrcA | points to the first input sequence |
| [in] | srcALen | length of the first input sequence |
| [in] | pSrcB | points to the second input sequence |
| [in] | srcBLen | length of the second input sequence |
| [out] | pDst | points to the location where the output result is written. Length 2 * max(srcALen, srcBLen) - 1. |
- Returns
- none
| void arm_correlate_fast_opt_q15 |
( |
const q15_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
const q15_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
q15_t * |
pDst, |
|
|
q15_t * |
pScratch |
|
) |
| |
- Parameters
-
| [in] | pSrcA | points to the first input sequence |
| [in] | srcALen | length of the first input sequence |
| [in] | pSrcB | points to the second input sequence |
| [in] | srcBLen | length of the second input sequence. |
| [out] | pDst | points to the location where the output result is written. Length 2 * max(srcALen, srcBLen) - 1. |
| [in] | pScratch | points to scratch buffer of size max(srcALen, srcBLen) + 2*min(srcALen, srcBLen) - 2. |
- Returns
- none
- Scaling and Overflow Behavior
- This fast version uses a 32-bit accumulator with 2.30 format. The accumulator maintains full precision of the intermediate multiplication results but provides only a single guard bit. There is no saturation on intermediate additions. Thus, if the accumulator overflows it wraps around and distorts the result. The input signals should be scaled down to avoid intermediate overflows. Scale down one of the inputs by 1/min(srcALen, srcBLen) to avoid overflow since a maximum of min(srcALen, srcBLen) number of additions is carried internally. The 2.30 accumulator is right shifted by 15 bits and then saturated to 1.15 format to yield the final result.
| void arm_correlate_fast_q15 |
( |
const q15_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
const q15_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
q15_t * |
pDst |
|
) |
| |
- Parameters
-
| [in] | pSrcA | points to the first input sequence |
| [in] | srcALen | length of the first input sequence |
| [in] | pSrcB | points to the second input sequence |
| [in] | srcBLen | length of the second input sequence |
| [out] | pDst | points to the location where the output result is written. Length 2 * max(srcALen, srcBLen) - 1. |
- Returns
- none
- Scaling and Overflow Behavior
- This fast version uses a 32-bit accumulator with 2.30 format. The accumulator maintains full precision of the intermediate multiplication results but provides only a single guard bit. There is no saturation on intermediate additions. Thus, if the accumulator overflows it wraps around and distorts the result. The input signals should be scaled down to avoid intermediate overflows. Scale down one of the inputs by 1/min(srcALen, srcBLen) to avoid overflow since a maximum of min(srcALen, srcBLen) number of additions is carried internally. The 2.30 accumulator is right shifted by 15 bits and then saturated to 1.15 format to yield the final result.
| void arm_correlate_fast_q31 |
( |
const q31_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
const q31_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
q31_t * |
pDst |
|
) |
| |
- Parameters
-
| [in] | pSrcA | points to the first input sequence |
| [in] | srcALen | length of the first input sequence |
| [in] | pSrcB | points to the second input sequence |
| [in] | srcBLen | length of the second input sequence |
| [out] | pDst | points to the location where the output result is written. Length 2 * max(srcALen, srcBLen) - 1. |
- Returns
- none
- Scaling and Overflow Behavior
- This function is optimized for speed at the expense of fixed-point precision and overflow protection. The result of each 1.31 x 1.31 multiplication is truncated to 2.30 format. These intermediate results are accumulated in a 32-bit register in 2.30 format. Finally, the accumulator is saturated and converted to a 1.31 result.
- The fast version has the same overflow behavior as the standard version but provides less precision since it discards the low 32 bits of each multiplication result. In order to avoid overflows completely the input signals must be scaled down. The input signals should be scaled down to avoid intermediate overflows. Scale down one of the inputs by 1/min(srcALen, srcBLen)to avoid overflows since a maximum of min(srcALen, srcBLen) number of additions is carried internally.
| void arm_correlate_opt_q15 |
( |
const q15_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
const q15_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
q15_t * |
pDst, |
|
|
q15_t * |
pScratch |
|
) |
| |
- Parameters
-
| [in] | pSrcA | points to the first input sequence |
| [in] | srcALen | length of the first input sequence |
| [in] | pSrcB | points to the second input sequence |
| [in] | srcBLen | length of the second input sequence |
| [out] | pDst | points to the location where the output result is written. Length 2 * max(srcALen, srcBLen) - 1. |
| [in] | pScratch | points to scratch buffer of size max(srcALen, srcBLen) + 2*min(srcALen, srcBLen) - 2. |
- Returns
- none
- Scaling and Overflow Behavior
- The function is implemented using a 64-bit internal accumulator. Both inputs are in 1.15 format and multiplications yield a 2.30 result. The 2.30 intermediate results are accumulated in a 64-bit accumulator in 34.30 format. This approach provides 33 guard bits and there is no risk of overflow. The 34.30 result is then truncated to 34.15 format by discarding the low 15 bits and then saturated to 1.15 format.
| void arm_correlate_opt_q7 |
( |
const q7_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
const q7_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
q7_t * |
pDst, |
|
|
q15_t * |
pScratch1, |
|
|
q15_t * |
pScratch2 |
|
) |
| |
- Parameters
-
| [in] | pSrcA | points to the first input sequence |
| [in] | srcALen | length of the first input sequence |
| [in] | pSrcB | points to the second input sequence |
| [in] | srcBLen | length of the second input sequence |
| [out] | pDst | points to the location where the output result is written. Length 2 * max(srcALen, srcBLen) - 1. |
| [in] | pScratch1 | points to scratch buffer(of type q15_t) of size max(srcALen, srcBLen) + 2*min(srcALen, srcBLen) - 2. |
| [in] | pScratch2 | points to scratch buffer (of type q15_t) of size min(srcALen, srcBLen). |
- Returns
- none
- Scaling and Overflow Behavior
- The function is implemented using a 32-bit internal accumulator. Both the inputs are represented in 1.7 format and multiplications yield a 2.14 result. The 2.14 intermediate results are accumulated in a 32-bit accumulator in 18.14 format. This approach provides 17 guard bits and there is no risk of overflow as long as
max(srcALen, srcBLen)<131072. The 18.14 result is then truncated to 18.7 format by discarding the low 7 bits and then saturated to 1.7 format.
| void arm_correlate_q15 |
( |
const q15_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
const q15_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
q15_t * |
pDst |
|
) |
| |
- Parameters
-
| [in] | pSrcA | points to the first input sequence |
| [in] | srcALen | length of the first input sequence |
| [in] | pSrcB | points to the second input sequence |
| [in] | srcBLen | length of the second input sequence |
| [out] | pDst | points to the location where the output result is written. Length 2 * max(srcALen, srcBLen) - 1. |
- Returns
- none
- Scaling and Overflow Behavior
- The function is implemented using a 64-bit internal accumulator. Both inputs are in 1.15 format and multiplications yield a 2.30 result. The 2.30 intermediate results are accumulated in a 64-bit accumulator in 34.30 format. This approach provides 33 guard bits and there is no risk of overflow. The 34.30 result is then truncated to 34.15 format by discarding the low 15 bits and then saturated to 1.15 format.
| void arm_correlate_q31 |
( |
const q31_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
const q31_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
q31_t * |
pDst |
|
) |
| |
- Parameters
-
| [in] | pSrcA | points to the first input sequence |
| [in] | srcALen | length of the first input sequence |
| [in] | pSrcB | points to the second input sequence |
| [in] | srcBLen | length of the second input sequence |
| [out] | pDst | points to the location where the output result is written. Length 2 * max(srcALen, srcBLen) - 1. |
- Returns
- none
- Scaling and Overflow Behavior
- The function is implemented using an internal 64-bit accumulator. The accumulator has a 2.62 format and maintains full precision of the intermediate multiplication results but provides only a single guard bit. There is no saturation on intermediate additions. Thus, if the accumulator overflows it wraps around and distorts the result. The input signals should be scaled down to avoid intermediate overflows. Scale down one of the inputs by 1/min(srcALen, srcBLen)to avoid overflows since a maximum of min(srcALen, srcBLen) number of additions is carried internally. The 2.62 accumulator is right shifted by 31 bits and saturated to 1.31 format to yield the final result.
| void arm_correlate_q7 |
( |
const q7_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
const q7_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
q7_t * |
pDst |
|
) |
| |
- Parameters
-
| [in] | pSrcA | points to the first input sequence |
| [in] | srcALen | length of the first input sequence |
| [in] | pSrcB | points to the second input sequence |
| [in] | srcBLen | length of the second input sequence |
| [out] | pDst | points to the location where the output result is written. Length 2 * max(srcALen, srcBLen) - 1. |
- Returns
- none
- Scaling and Overflow Behavior
- The function is implemented using a 32-bit internal accumulator. Both the inputs are represented in 1.7 format and multiplications yield a 2.14 result. The 2.14 intermediate results are accumulated in a 32-bit accumulator in 18.14 format. This approach provides 17 guard bits and there is no risk of overflow as long as
max(srcALen, srcBLen)<131072. The 18.14 result is then truncated to 18.7 format by discarding the low 7 bits and saturated to 1.7 format.