 |
OpenGL ES SDK for Android
ARM Developer Center
|
|
OpenGL ES SDK for Android
ARM Developer Center
|
This document will give you an introduction to compute shaders in OpenGL ES 3.1, how they fit into the rest of OpenGL ES and how you can make use of it in your application. Using compute shaders effectively requires a new mindset where parallel computation is exposed more explicitly to developers. With this explicitness, various new primitives are introduced which allows compute shader threads to share access to memory and synchronize execution.
For the most part, computer graphics is a so called "embarrassingly parallel" problem. If we look at drawing a scene we can process all vertices and the resulting fragments in parallel and separately. Getting good parallelism for such a case is fairly straight forward, and does not require much from an OpenGL ES application. GPUs are designed to handle these workloads well.
A good side effect of embarrassingly parallel computation is that from an API standpoint, there is no need to explicitly state the number of threads needed for a task and manage them manually. We only provide shader code for the task that is to be run in parallel.
We do not need to care how the loop is implemented, or in which order the loop is executed. We only implement run_shader(), or in our case, our shader code. In compute terms, the loop body, run_shader(), is commonly called the "kernel".
Before compute shaders, there were multiple ways to expose embarrassingly parallel computation in OpenGL ES. A common way to perform computation is by rasterizing a quad and performing arbitrary computation in the fragment shader. The results can then be written to a texture. Another approach is to use transform feedback to perform arbitrary computation in the vertex shader.
A common theme in vertex and fragment shading is that once the shader starts executing, it is already known where the shader will write data and the shader invocation has no knowledge of other shader invocations running in parallel. In vertex shading, our input is vertex attributes and we output varyings and gl_Position. For fragment, we take interpolated varyings as input and output one or multiple colors. Using textures and uniform buffer objects, we are able to read from arbitrary memory in vertex and fragment, but we are still only allowed to write to one specific location.
Moving to compute, we have no notion of vertex attribute, varyings, or output colors. Once a compute thread starts executing, it has no prior knowledge of where it will read data from nor where it will write to. Since every compute thread executes the same kernel code, we need some way for threads to do different things. The approach that compute APIs have taken is to give each thread a unique identifier.
Consider the difference between:
and
In the latter case, we explicitly state that we want to process elements independently, where in the first, we're forced to do so by design. As we see, transform feedback can be considered a special case of compute where inputs and output are mapped one-to-one.
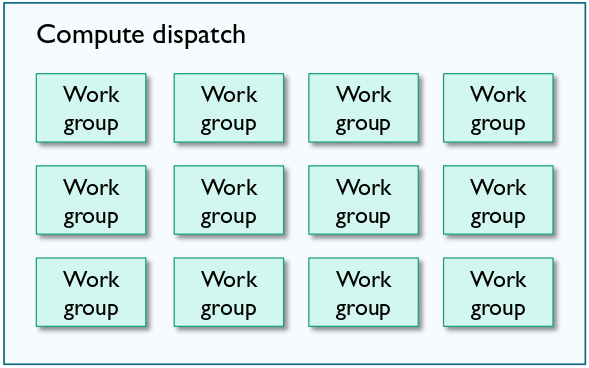
A typical compute job can span hundreds of thousands of threads, just like a quad being rasterized to a full screen can easily cover millions of pixels. It is clear that even a GPU cannot feasibly keep track of so many threads at one time. We do not have enough hardware for so many threads to execute at the same time.
Instead, we subdivide our threads into work groups which consist of a fixed number of threads. This is a smaller collection of threads that can run in parallel. Individual work groups however, are completely independent. A valid implementation could now look like
The number of threads in the work group is defined in the compute shader itself. To do this, we use a layout qualifier as such:
In OpenGL ES, implementations must support at least 128 threads in a work group. It is possible to check glGetIntegerv(GL_MAX_COMPUTE_WORK_GROUP_INVOCATIONS) in run-time to get implementation-specific limits.
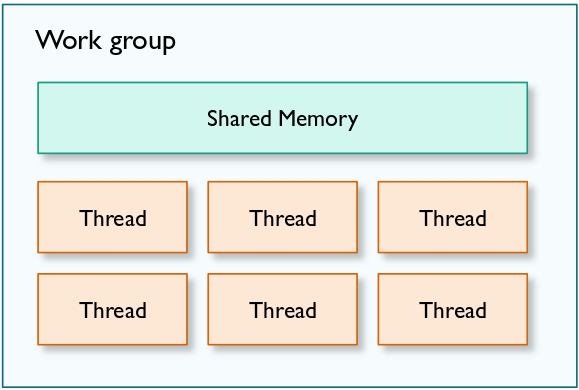
In OpenGL ES compute shaders, there are various ways for individual threads to get some unique identification.
Note the three dimensional values. In compute applications, it is often desirable to organize the work in more than one dimension. For image processing, it makes sense to use two dimensions, while processing volumetric 3D data makes sense to do using three dimensions.
It's important to note that this work group scheme is not new. This is the common model used by all major compute APIs, and skills learned by coding against this model can be applied to APIs like OpenCL as well. If you have used other compute APIs in the past, the OpenGL model should feel familiar.
Compute shaders are still shaders just like fragment and vertex shaders. The difference however, is that compute shaders are single-stage. You cannot link a compute shader with a vertex shader for example.
To compile and link a compute program, we can do something like this
To execute a compiled shader, it works similarly to regular draw calls.
We explicitly state how many work groups we want to dispatch. The number of work groups will be work_groups_x * work_groups_y * work_groups_z organized in three dimensions as we specify ourselves.
Conceptually, this compute job runs asynchronous with the rest of OpenGL ES, and we will later look into how we synchronize with the rest of OpenGL ES.
While OpenGL ES has many different buffer types, there were no buffer types which could support fully random access writing. Shader storage buffer objects, or SSBO for short is the new general purpose buffer object in OpenGL ES. Implementations must support SSBOs of at least 128 MiB, which is a tremendous increase compared to the 16 KiB that uniform buffer objects must support.
Just like uniform buffer objects, SSBOs are bound in an indexed way as a shader can have multiple SSBOs in use.
To create an SSBO and upload data to it, use glBindBuffer() as normal.
GL_SHADER_STORAGE_BUFFER target, no matter how they were originally created.A problem with using e.g. uniform buffer objects is that the binary layout for CPU and GPU must be the same. std140 layout is the standard packing layout that is guaranteed to be the same for every implementation which makes it more maintainable and easy to use uniform buffer objects. std140 has some deficiencies however. One major problem with std140 is that arrays of scalars cannot be tightly packed. E.g. a float array[1024]; will have element packing like a vec4, which quadruples the memory requirements. The workaround for that has been always packing in vec4s, but if the underlying data is inherently scalar, such workarounds are at best annoying.
std430 improves packing, and ensures that scalar arrays can be tightly packed. std430 is only available for SSBOs.
When processing large amounts of data, it is often unknown in the shader itself how large a buffer object really is. In other buffer objects, we typically have to give it a size anyways, like
With SSBOs, this restriction is lifted, and we can declare the last member of a struct without size.
It is possible to query the number of elements during shader execution using elements.length() like any other GLSL array. The length parameter is derived from the buffer that is bound to the binding point.
To give the minimally useful compute shader, let's assume we want to do an element-wise multiplies.
Similarly to the situation with buffer objects before, textures have been read-only. The standard way to write to a texture has been via framebuffer objects and fragment shading. For compute, a new and more direct interface to deal with writeable textures is introduced.
We have had terminology like a texture and sampler before, but to expose writeable textures a shader image is introduced. Shader images have support for random-access reads (like texelFetch), and random access writes. An interesting feature is that they also support reinterpreting the underlying datatype. Unlike regular textures, shader images support no filtering, and as they are basically raw texel access, the underlying datatype can be reinterpreted however the shader wants. The restriction is that the actual texture format and reinterpreted format must have the same size.
Layering is also supported. This means that a cube map, 2D texture array or 3D texture can be bound and the shader has full access to any cube face, array index or 3D texture slice. It is also possible to disable layering and only bind a single layer as a plain 2D image.
Binding a shader image is similar to binding a texture.
In the shader code, we would do something like:
In GLSL, we can now use imageLoad(), imageStore() and imageSize().
glUniform1i() to bind shader images to a particular "unit" like with regular samplers. This is not supported, and you should use layout(binding = UNIT) in the shader code instead. This is the modern OpenGL (ES) way of doing things anyways.glTexStorage*()-like functions, and not glTexImage2D().A major feature of compute is that since we have the concept of a work group, we can now give the work group some shared memory which can be used by every thread in the work group. This allows compute shader threads to share their computation with other threads which can make or break certain parallel algorithms.
A nice use case for shared memory is that it's sometimes possible to perform multi-pass algorithms in a single pass instead by using shared memory to store data between passes. Shared memory is typically backed by either cache or specialized fast local memory. Multi-pass approaches using fragment shaders need to flush out results to textures every pass, which can get very bandwidth intensive.
To declare shared memory for a compute work group, do this:
To properly make use of shared memory however, we will need to introduce some new synchronization primitives first.
With compute shaders, multiple threads can perform operations on the same memory location. Without some new atomic primitives, accessing such memory safely and correct would be impossible.
Atomic operations fetch the memory location, perform the operation and write back to memory atomically. Thus, multiple threads can access the same memory without data races. Atomic operations are supported for uint and int datatypes. Atomic operations always return the value that was in memory before applying the operation in question.
There are two interfaces for using atomics in OpenGL ES 3.1, explained below.
The first interface is the older atomic counters interface. It is a reduced interface which only supports basic increments and decrements.
In a shader, you can declare an atomic_uint like this:
Atomic counters are backed by a buffer object GL_ATOMIC_COUNTER_BUFFER. Just like uniform buffers, they are indexed buffers. To bind an indexed buffer, use
or
GL_ATOMIC_COUNTER_BUFFER. Note that there are restrictions to the number of counters you can use.A more flexible interface to atomics is when using shared memory or SSBOs. Various atomic*() functions are provided which accept variables backed by shared or SSBO memory.
For example:
With an extension to OpenGL ES 3.1, GL_OES_shader_image_atomic, atomic operations are supported on shader images as well.
OpenGL ES from an API standpoint is an in-order model. The API appears to execute GL commands as-if every command is completed immediately before moving on to the next GL command. Of course, any reasonable OpenGL ES implementation will not do this, and opt for a buffered and/or deferred approach. In addition, for various hazard scenarios like reading from a texture after rendering a scene to it, the driver needs to ensure proper synchronization, etc. Users of OpenGL ES do not have to think about these low-level details. The main reason why this can be practical from an API standpoint is that up until now, the API have had full control of where shaders write data. Either we wrote data to textures via FBOs, or to buffers with transform feedback. The driver could track which data has been touched and add the extra synchronization needed to operate correctly.
With compute however, the model changes somewhat. Now, compute shaders can write to SSBOs, images, atomics and shared memory. Whenever we perform such writes, we need to ensure proper synchronization ourselves.
Being able to have writes from one thread be visible to another thread running in parallel requires coherent memory. We need some new qualifiers to express how we are going to access the memory, and OpenGL ES 3.1 defines these new qualifiers.
To use one or multiple qualifiers, we can apply them to SSBOs and shader images like this:
A variable declared coherent means that a write to that variable will eventually be made visible to other shader invocations in the same GL command. This is only useful if you expect that other threads are going to read the data that one thread will write. Threads which are reading data from coherent writes must also read from variables marked as coherent.
These are designed to express read-only or write-only behavior. Atomic operations both read and write variables, and variables cannot be declared with either if atomics are used.
These are fairly obscure. Their meanings are the same as in C. Restrict expresses that buffers or images do not alias each other, while volatile means buffer storage can change at any time, and must be reloaded every time.
Consider a probable use of compute where we're computing a vertex buffer and drawing the result:
If this were render-to-texture or similar, code like this would be correct since the OpenGL ES driver ensures correct synchronization. However, since we wrote to an SSBO in a compute shader, we need to ensure that our writes are properly synchronized with the rest of OpenGL ES ourselves.
To do this, we use a new function, glMemoryBarrier() and our corrected version looks like:
It's important to remember the semantics of glMemoryBarrier(). As argument it takes a bitfield of various buffer types. We specify how we will read data after the memory barrier. In this case, we are writing the buffer via an SSBO, but we're reading it when we're using it as a vertex buffer, hence GL_VERTEX_ATTRIB_ARRAY_BARRIER_BIT.
Another detail is that we only need a memory barrier here. We do not need some kind of "execution barrier" for the compute dispatch itself.
While the API level memory barriers order memory accesses across GL commands, we also need some shader language barriers to order memory accesses within a single dispatch.
To understand memory barriers, we first need to consider memory ordering. An important problem with multi-threaded programming is that while memory transactions within a single thread might happen as expected, when other threads see the data written by the thread, the order of which the memory writes become visible might not be well defined depending on the architecture. In the CPU space, this problem also exists, where it's often referred to as "weakly ordered memory".
To fully grasp the consequences of weakly ordered memory is a long topic on its own. The section here serves to give some insight as to why ordering matters, and why we need to think about memory ordering when we want to share data with other threads running in parallel.
To illustrate why ordering matters, we can consider two threads in this classic example. Thread 1 is a producer which writes data, and thread 2 consumes it.
Even if thread 1 wrote to A, then B, it is possible that the memory system completes the write to B first, then A. If thread 2 reads B and A with just the right timing, the odd-ball case above is possible.
To resolve this case, we need to employ memory barriers to tell the memory system that a strict ordering guarantee is required. OpenGL ES defines several memory barriers.
memoryBarrier()memoryBarrierShared()memoryBarrierImage()memoryBarrierBuffer()memoryBarrierAtomicCounter()groupMemoryBarrier()The memoryBarrier*() functions control memory ordering for a particular memory type. memoryBarrier() enforces ordering for all memory accesses. groupMemoryBarrier() enforces memory ordering like memoryBarrier(), but only for threads in the same work group. All memory barriers except for groupMemoryBarrier() and memoryBarrierShared() enforce ordering for all threads in the compute dispatch.
The memory barrier ensures that all memory transactions before the barrier must complete before proceeding. Memory accesses below the barrier cannot be moved over the barrier.
Looking at our example, we can now fix it like this:
While ordering scenarios like these are rarely relevant for compute, memory barriers in OpenGL ES also ensure visibility of coherent writes. If a thread is writing to coherent variables and we want to ensure that our writes become visible to other threads, we need memory barriers. For example:
Memory barriers only ensure ordering for memory, not execution. Parallel algorithms often require some kind of execution synchronization as well.
A cornerstone of GPU compute is the ability to synchronize threads in the same workgroup. By having fine-grained synchronization of multiple threads, we are able to implement algorithms where we can safely know that other threads in the work group have done their tasks.
For example, let's assume a case where we want to read some data from an SSBO, perform some computation on the data and share the results with the other threads in the work group.
In this sample, we're missing proper synchronization. For example, we have a fundamental problem that we aren't guaranteed that other threads in the work group have executed perform_computation() and written out the result to someSharedData0. If we let one thread proceed with execution prematurely, we will read garbage, and the computation will obviously be wrong. To solve this problem we need to employ memory barriers and execution barriers.
barrier() also implies that shared memory is synchronized. While this is often the case from an implementation point of view, the OpenGL ES specification is not as clear on this and to avoid potential issues, use of a proper memoryBarrierShared() before barrier() is highly recommended. For any other memory type than shared, the specification is very clear on that the approprimate memory barrier must be used.barrier() is a quite special function due to its synchronization properties. If one of the threads in the work group does not hit the barrier(), it conceptually means that no other thread can ever continue, and we would have a deadlock.
These situations can arise in divergent code, and it's necessary for the programmer to ensure that either every thread calls the barrier, or no threads call it. It's legal to call barrier() in a branch (or loop), as long as the flow control is dynamically uniform. E.g.:
Compute-like functionality such as SSBOs, shader image load/store and atomic counters are optionally supported in vertex and fragment shaders as well in OpenGL ES 3.1. To test if these features are supported, various glGetIntegerv() queries tells the application if these features are supported.
GL_MAX_*_ATOMIC_COUNTERSGL_MAX_*_SHADER_STORAGE_BLOCKSGL_MAX_*_IMAGE_UNIFORMSwhere * can be replaced with the appropriate shader stage. In OpenGL ES 3.1, these values are 0 if not supported by the implementation.
glMemoryBarrierByRegion() is a special variant of glMemoryBarrier() which only applies for fragment shaders. It works the same way as glMemoryBarrier() except that it only guarantees memory ordering for fragments belonging to the same "region" of the framebuffer. The region is implementation defined, and can be as small as one pixel.
This can be useful especially for tiled GPU architectures. Consider:
Since glMemoryBarrier() must guarantee visibility, we need to wait for every fragment in draw_call_1 to complete to ensure that our ordering guarantee is met. Since the fragments can hit anywhere in the entire framebuffer, this effectively means that we have to flush out our scene to memory, which we really want to avoid on tiled architectures.
However, if we only care about ordering between fragments which hit the same region (pixel in framebuffer). We can avoid flushing out tile buffers to memory.
OpenGL ES 3.1 defines a model where per-fragment tests like depth testing happen after fragment shader execution. This is needed to accomodate cases where the fragment shader modifies depth.
Modifying depth in the fragment shaders however is uncommon, and GPUs will tend to avoid executing the fragment shader altogether if it can since it already knows the fragment depth and can do the depth test early.
With random access writes in fragment shaders, the situation becomes more complicated. We could do early-Z because there were no side effects in the fragment shader, but this model breaks down once side effects like shader image load/store is used. Since early-Z is so important, we can now force early depth testing in the fragment shader.

