 |
OpenGL ES SDK for Android
ARM Developer Center
|
|
OpenGL ES SDK for Android
ARM Developer Center
|
Demonstration of shadow mapping functionality using OpenGL ES 3.0.
This tutorial assumes that you already have basic OpenGL ES knowledge, and have read and understood the Normal Mapping, Lighting and Texture Cube tutorials.

The application displays two cubes on a plane which are lit by directional and spot lights. The location and direction of the spot light source (represented by a small yellow cube flying above the scene) in 3D space are regularly updated. The cube and plane models are shadow receivers, but only the cubes are shadow casters. The application uses shadow mapping for rendering and displaying shadows.
In the application we are rendering a horizontally located plane, on top of which we lay two cubes. There is also a single cube flying above the scene which represents the spot light source. Let us now focus on generating the geometry that will be rendered.
In the application we are using two program objects: one responsible for rendering the scene, which consists of a plane and two cubes with all the lighting and shadows applied, and a second one, used for rendering a single cube (the yellow one flying above the scene) that represents the spot light source. We will now focus on the first program object, as rendering the single cube on a screen should be already a well-know technique for the reader (or will be after reading this tutorial).
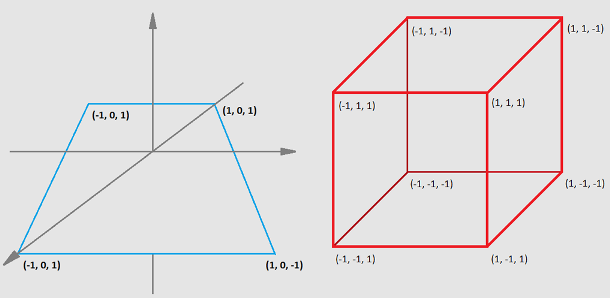
First of all, we need to have the coordinates of vertices that make up a cubic or plane shape. Please note that there will also be lighting applied, which means that we will need normals as well.
Geometry data will be stored and then used by objects that are generated with the following commands:
There is one extra buffer object generated, which ID is stored in the uniformBlockDataBufferObjectId variable. This one is not needed at this step, so you can ignore it.
Geometry data is then generated and copied to specific buffer objects. For more details on how the coordinates of vertices are calculated, please refer to the implementation of those functions.
Generate geometry data.
Fill buffer objects with data.
In the program object, geometry vertices are referred to via the attributes, which is rather obvious.
This is why we need to query for the attribute location within the program object responsible for scene rendering (note that all of the following functions need to be called for the active program object).
As you can see above, we are querying for the locations of coordinates only, without specifying the cube or plane ones. This is because we are using only one program object to render both the plane and the cubes. Rendering specific geometry is achieved by using proper Vertex Attrib Arrays. Let's look at how it is implemented.
Now, by calling glBindVertexArray() with the proper parameter, we can control which object (cubes or plane) is going to be rendered. Please refer to:
The final thing is to make the actual draw call, which can be achieved by:
We wanted to draw two cubes that are laid on a plane. This is why we use the glDrawArraysInstanced() call rather than glDrawArrays(). Thanks to that there will be exactly 2 instances of the same object drawn on a screen.
To calculate the shadow map we need to create a depth texture, which will be used to store the results. It is achieved in some basic steps, which you should already know, but let us describe this one more time.
Generate texture object and bind it to the GL_TEXTURE_2D target.
Specify the texture storage data type.
We wanted our shadow to be more precise, this is why the depth texture resolution is bigger than normal scene size. Please refer to:
Set texture object parameters. The new thing here is to set GL_TEXTURE_COMPARE_MODE to the value of GL_COMPARE_REF_TO_TEXTURE which leads to r texture coordinate to be compared to the value in the currently bound depth texture.
The next thing we have to do to implement the render to texture mechanism is to:
We wanted the spot light source position to be updated per each frame. This is why the shadow map will need to be updated as well, as the perspective from which a spot light is "looking into" the scene is different for each frame.
In the shader, we are using a uniform: a boolean flag indicating, whether the plane or cubes are being rendered. Thanks to that, there will be a different position used, which are specific for each geometry.
Get uniform location
Set uniform value. False, if cubes are rendered.
True, if a plane is rendered.
Owing to the fact that the shadow map texture is bigger than the normal scene (as already mentioned above), we have to remember to adjust the viewport.
Our scene is rather simple: there are two cubes placed on the top of a plane. We can introduce some optimisation here, which means the back faces will be culled. We are also setting the polygon offset to eliminate z-fighting in the shadows. Those settings are used only if enabled.
What we need to do is to enable depth testing. When this is enabled, the depth values will be compared and the result will be stored in the depth buffer.
In this step, we want to generate the depth values only, which means we are allowed to disable writing to each framebuffer colour component.
Finally we are ready for the actual rendering.
If we would like to use the generated depth texture data in a program object, it is enough to query for a shadow sampler uniform location and set the depth texture object as input value for this uniform.
Those are basically all the steps we need to proceed in the API. The main mechanism of the shadow mapping technique is handled by the program object. Please look at the shaders shown below.
Vertex shader code
We use one program object to render the cubes and plane from the camera and light point of view. The vertex shader just uses different input data to render the specific geometry and different matrices are used for translating the vertices into a specific space. There is however one important step which has not been mentioned before.
If we are rendering a geometry from the spot light’s point of view (to get depth values which are then stored in the shadowMap texture), then we need to sample the texture to get the depth value of a specific fragment, but this time the camera’s point of view is taken into account. We have to somehow convert one space into another. And this is why we are calculating the outputViewToTextureMatrix matrix.
A bias matrix helps us with converting coordinates from eye space (from a range <-1, 1>) to values from texture coordinates range: <0, 1>.
The whole idea is represented with the schema shown below.

When we get this value, we are ready to issue the fragment shader operations. There is directional lighting implemented, which should be clear for a reader. There are also spot light calculations issued.
Fragment shader code
The main idea behind this is simple: we take a fragment, check, whether it is placed inside the spot light cone (with checking the angle between the fragment and the spot light direction). Then the fragment is considered as lit by a spot light, or outside: in this case no spot light is added to a fragment. In the situation when a fragment is lit by the spot light, we need to check whether it should be obscured by a shadow.
This is where the previously calculated outputViewToTextureMatrix matrix will be used. We need to sample the depth texture with properly calculated coordinates for a given fragment and compare the retrieved value with the model depth. In the comparison there is also a shadowMapBias added to avoid artefacts.

